
July 29, 2021 08:57 by
 Peter
Peter
Master-Slave database design is usually designed to replicate to one or more database servers. In this scenario, we have a master/slave relationship between the original database and the copies of databases.

A master database only supports the write operations and the slave database only supports read operations. Basically, the master database will handle the insert, delete and update commands whereas the slave databases will handle the select command.
The below image shows a master database with multiple slave databases.
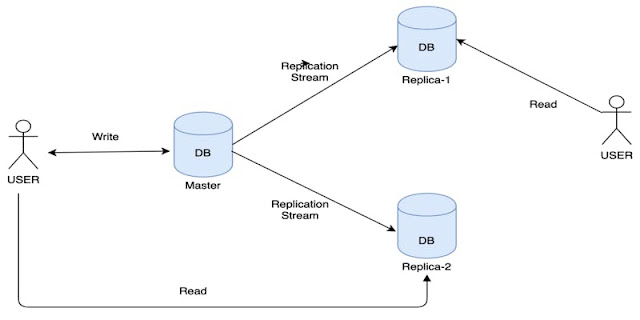
Advantages of Master/Slave Design
Availability
We have replicated the master data across multiple locations. So in case, a slave database goes offline, then we have other slave databases to handle the read operations.
Performance
As the master/slave model has multiple slave database servers, more queries can be processed in parallel.
Failover alleviating
We can set up a master and a slave (or several slaves), and then write a script that monitors the master to check whether it is up. Then instruct our applications and the slaves to change master in case of failure.
Problem with Master/Slave Design
One of the major problems with this design is that if a user has changed his/her profile username. This request will go into the master database. It takes some time to replicate the change in the slave databases. In case the customer refreshes the profile, he/she will still see the old data because the changes have not yet synced from the Master to Slave.